🚀 Voice Mode
AIアシスタントによる自然な音声会話を実現します。Voice Modeは、Model Context Protocol (MCP) を通じて、Claude、ChatGPT、その他の大規模言語モデル (LLM) と人間に近い音声対話を可能にします。
インストール方法: uvx voice-mode | pip install voice-mode | getvoicemode.com




🚀 クイックスタート
📖 別のツールを使用していますか? Cursor、VS Code、Gemini CLIなどの 統合ガイド を参照してください!
npm install -g @anthropic-ai/claude-code
curl -LsSf https://astral.sh/uv/install.sh | sh
claude mcp add --scope user voice-mode uvx voice-mode
export OPENAI_API_KEY=your-openai-key
claude converse
✨ 主な機能
- 🎙️ 音声会話 - Claudeと質問をし、応答を聴くことができます。
- 🔄 複数の通信手段 - ローカルマイクまたはLiveKitルームベースの通信をサポートします。
- 🗣️ OpenAI互換 - 任意の音声認識 (STT) / 音声合成 (TTS) サービス (ローカルまたはクラウド) と互換性があります。
- ⚡ リアルタイム - 自動的に最適な通信手段を選択し、低遅延の音声対話を実現します。
- 🔧 MCP統合 - Claude Desktopや他のMCPクライアントとシームレスに連携します。
- 🎯 無音検出 - 話を止めると自動的に録音を停止します (待ち時間が不要になります!)
📦 インストール
前提条件
- Python >= 3.10
- Astral UV - パッケージマネージャー (
curl -LsSf https://astral.sh/uv/install.sh | sh でインストール)
- OpenAI APIキー (または互換性のあるサービス)
システム依存関係
Ubuntu/Debian
sudo apt update
sudo apt install -y python3-dev libasound2-dev libasound2-plugins libportaudio2 portaudio19-dev ffmpeg pulseaudio pulseaudio-utils
WSL2ユーザーへの注意: WSL2では、マイクアクセスに追加のオーディオパッケージ (pulseaudio、libasound2-plugins) が必要です。問題が発生した場合は、WSL2マイクアクセスガイド を参照してください。
Fedora/RHEL
sudo dnf install python3-devel alsa-lib-devel portaudio-devel ffmpeg
macOS
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
brew install portaudio ffmpeg
Windows (WSL)
WSL内でUbuntu/Debianの手順に従ってください。
NixOS
Voice Modeには、必要なすべての依存関係が含まれたflake.nixがあります。以下のいずれかの方法で使用できます。
- 開発用シェルを使用する (一時的):
nix develop github:mbailey/voicemode
- システム全体にインストールする (以下のインストールセクションを参照)
クイックインストール
claude mcp add --scope user voice-mode uvx voice-mode
claude mcp add voice-mode nix run github:mbailey/voicemode
uvx voice-mode
pip install voice-mode
nix run github:mbailey/voicemode
AIコーディングアシスタントの設定
📖 詳細なセットアップ手順を探していますか? 各ツールの詳細な手順については、包括的な 統合ガイド を確認してください!
以下は、クイック設定のスニペットです。完全なインストールとセットアップ手順については、上記の統合ガイドを参照してください。
Claude Code (CLI)
claude mcp add voice-mode -- uvx voice-mode
または環境変数を使用する場合:
claude mcp add voice-mode --env OPENAI_API_KEY=your-openai-key -- uvx voice-mode
Claude Desktop
macOS: ~/Library/Application Support/Claude/claude_desktop_config.json
Windows: %APPDATA%\Claude\claude_desktop_config.json
{
"mcpServers": {
"voice-mode": {
"command": "uvx",
"args": ["voice-mode"],
"env": {
"OPENAI_API_KEY": "your-openai-key"
}
}
}
}
Cline
ClineのMCP設定に追加します。
Windows:
{
"mcpServers": {
"voice-mode": {
"command": "cmd",
"args": ["/c", "uvx", "voice-mode"],
"env": {
"OPENAI_API_KEY": "your-openai-key"
}
}
}
}
macOS/Linux:
{
"mcpServers": {
"voice-mode": {
"command": "uvx",
"args": ["voice-mode"],
"env": {
"OPENAI_API_KEY": "your-openai-key"
}
}
}
}
Continue
.continue/config.json に追加します。
{
"experimental": {
"modelContextProtocolServers": [
{
"transport": {
"type": "stdio",
"command": "uvx",
"args": ["voice-mode"],
"env": {
"OPENAI_API_KEY": "your-openai-key"
}
}
}
]
}
}
Cursor
~/.cursor/mcp.json に追加します。
{
"mcpServers": {
"voice-mode": {
"command": "uvx",
"args": ["voice-mode"],
"env": {
"OPENAI_API_KEY": "your-openai-key"
}
}
}
}
VS Code
VS CodeのMCP設定に追加します。
{
"mcpServers": {
"voice-mode": {
"command": "uvx",
"args": ["voice-mode"],
"env": {
"OPENAI_API_KEY": "your-openai-key"
}
}
}
}
Windsurf
{
"mcpServers": {
"voice-mode": {
"command": "uvx",
"args": ["voice-mode"],
"env": {
"OPENAI_API_KEY": "your-openai-key"
}
}
}
}
Zed
Zedのsettings.jsonに追加します。
{
"context_servers": {
"voice-mode": {
"command": {
"path": "uvx",
"args": ["voice-mode"],
"env": {
"OPENAI_API_KEY": "your-openai-key"
}
}
}
}
}
Roo Code
- VS Codeの設定 (
Ctrl/Cmd + ,) を開きます。
- 設定検索バーで "roo" を検索します。
- "Roo-veterinaryinc.roo-cline → settings → Mcp_settings.json" を見つけます。
- "settings.jsonで編集" をクリックします。
- Voice Modeの設定を追加します。
{
"mcpServers": {
"voice-mode": {
"command": "uvx",
"args": ["voice-mode"],
"env": {
"OPENAI_API_KEY": "your-openai-key"
}
}
}
}
代替インストールオプション
Dockerを使用する場合
docker run -it --rm \
-e OPENAI_API_KEY=your-openai-key \
--device /dev/snd \
-v /tmp/.X11-unix:/tmp/.X11-unix \
-e DISPLAY=$DISPLAY \
ghcr.io/mbailey/voicemode:latest
pipxを使用する場合
pipx install voice-mode
ソースからインストールする場合
git clone https://github.com/mbailey/voicemode.git
cd voicemode
pip install -e .
NixOSインストールオプション
1. nix profileでインストールする (ユーザー全体):
nix profile install github:mbailey/voicemode
2. NixOS設定に追加する (システム全体):
environment.systemPackages = [
(builtins.getFlake "github:mbailey/voicemode").packages.${pkgs.system}.default
];
3. home-managerに追加する:
home.packages = [
(builtins.getFlake "github:mbailey/voicemode").packages.${pkgs.system}.default
];
4. インストールせずに実行する:
nix run github:mbailey/voicemode
💻 使用例
設定が完了したら、Claudeに以下のプロンプトを試してみてください。
👨💻 プログラミングと開発
"Let's debug this error together" - 問題を口頭で説明し、コードを貼り付けて、解決策を議論します。"Walk me through this code" - Claudeに複雑なコードを説明してもらいながら、質問をします。"Let's brainstorm the architecture" - 自然な会話を通じてシステムを設計します。"Help me write tests for this function" - 要件を説明し、口頭で反復作業を行います。
💡 一般的な生産性向上
"Let's do a daily standup" - プレゼンテーションを練習したり、考えを整理します。"Interview me about [topic]" - 質問と回答を繰り返して面接の準備をします。"Be my rubber duck" - 問題を大声で説明して解決策を見つけます。
🎯 音声コントロール機能
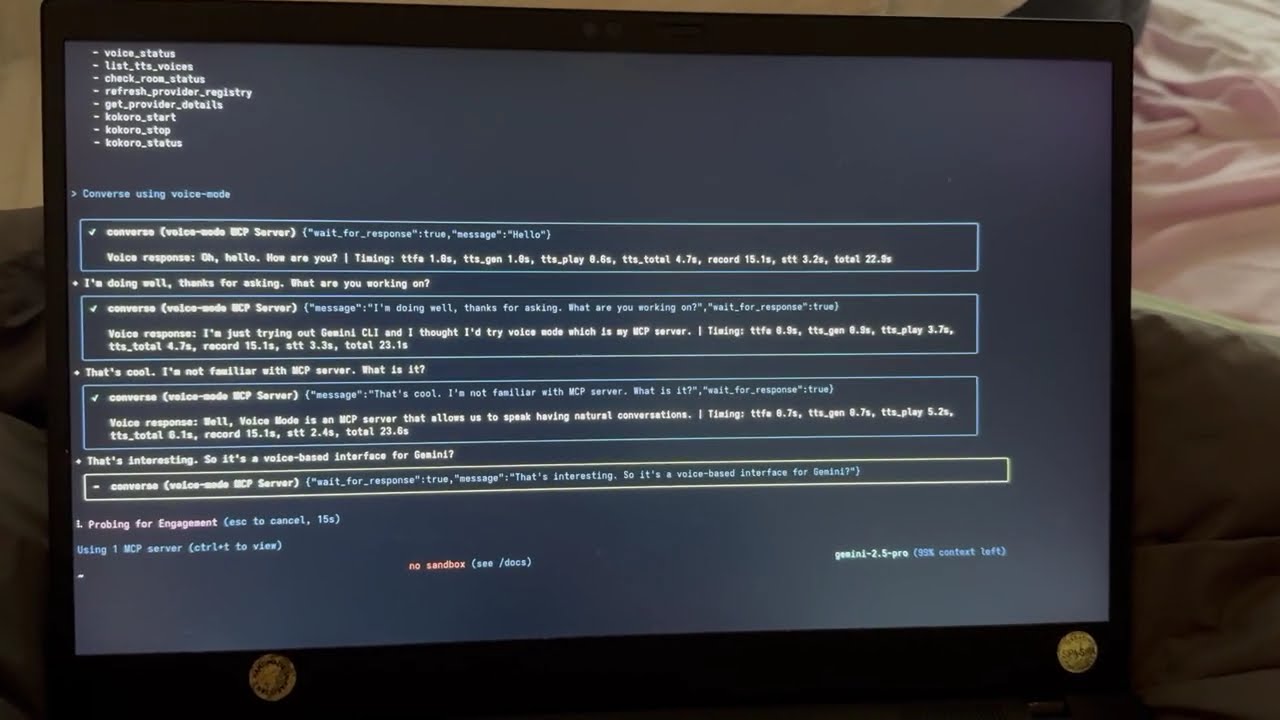
"Read this error message" (Claudeが読み上げ、あなたの応答を待ちます)"Just give me a quick summary" (Claudeが待たずに読み上げます)converse("message", wait_for_response=False) を使用して、片方向のアナウンスを行います。
converse 関数は、音声対話を自然に行うための主要なインターフェースで、デフォルトではあなたの応答を自動的に待ち、リアルな会話の流れを作り出します。
📚 ドキュメント
📚 voice-mode.readthedocs.ioで完全なドキュメントを読む
始めるには
- 統合ガイド - すべてのサポートされているツールのステップバイステップのセットアップ手順
- 設定ガイド - すべての環境変数のリファレンス
開発
- uv/uvxの使用 - uvとuvxによるパッケージ管理
- ローカル開発 - 開発環境のセットアップガイド
- オーディオフォーマット - オーディオフォーマットの設定と移行
- 統計ダッシュボード - パフォーマンスの監視とメトリクス
サービスガイド
- Whisper.cppのセットアップ - ローカルの音声認識の設定
- Kokoroのセットアップ - 複数の音声オプションを持つローカルの音声合成の設定
- LiveKitの統合 - リアルタイムの音声通信
トラブルシューティング
- WSL2マイクアクセス - WSL2のオーディオセットアップ
- 移行ガイド - 古いバージョンからのアップグレード
🔧 技術詳細
サポートされるツール
Voice Modeは、お気に入りのAIコーディングアシスタントと互換性があります。
- 🤖 Claude Code - Anthropicの公式CLI
- 🖥️ Claude Desktop - デスクトップアプリケーション
- 🌟 Gemini CLI - GoogleのCLIツール
- ⚡ Cursor - AIファーストのコードエディター
- 💻 VS Code - MCPプレビューサポート付き
- 🦘 Roo Code - VS Code内のAI開発チーム
- 🔧 Cline - 自律型コーディングエージェント
- ⚡ Zed - 高性能エディター
- 🏄 Windsurf - Codeiumによるエージェント型IDE
- 🔄 Continue - オープンソースのAIアシスタント
ツールの説明
| ツール |
説明 |
主要パラメータ |
converse |
音声会話を行う - 話して、必要に応じて聴きます |
message、wait_for_response (デフォルト: true)、listen_duration (デフォルト: 30s)、transport (自動/ローカル/LiveKit) |
listen_for_speech |
音声を聴き、テキストに変換します |
duration (デフォルト: 5s) |
check_room_status |
LiveKitルームの状態と参加者を確認します |
なし |
check_audio_devices |
使用可能なオーディオ入力/出力デバイスをリストします |
なし |
start_kokoro |
Kokoro TTSサービスを起動します |
models_dir (オプション、デフォルト: ~/Models/kokoro) |
stop_kokoro |
Kokoro TTSサービスを停止します |
なし |
kokoro_status |
Kokoro TTSサービスの状態を確認します |
なし |
install_whisper_cpp |
ローカルの音声認識用にwhisper.cppをインストールします |
install_dir、model (デフォルト: base.en)、use_gpu (自動検出) |
install_kokoro_fastapi |
ローカルの音声合成用にkokoro-fastapiをインストールします |
install_dir、port (デフォルト: 8880)、auto_start (デフォルト: true) |
注意: converse ツールは、音声対話の主要なインターフェースで、話すことと聴くことを自然な流れで組み合わせます。
新機能: install_whisper_cpp と install_kokoro_fastapi ツールは、無料でプライベートなオープンソースの音声サービスをローカルにセットアップするのに役立ちます。詳細な使用方法については、インストールツールドキュメント を参照してください。
設定
- 📖 統合ガイド - 各ツールのステップバイステップのセットアップ
- 🔧 設定リファレンス - すべての環境変数
- 📁 設定例 - すぐに使える設定ファイル
クイックセットアップ
必要な設定は、OpenAI APIキーのみです。
export OPENAI_API_KEY="your-key"
オプション設定
export STT_BASE_URL="http://127.0.0.1:2022/v1"
export TTS_BASE_URL="http://127.0.0.1:8880/v1"
export TTS_VOICE="alloy"
export LIVEKIT_URL="wss://your-app.livekit.cloud"
export LIVEKIT_API_KEY="your-api-key"
export LIVEKIT_API_SECRET="your-api-secret"
export VOICEMODE_DEBUG="true"
export VOICEMODE_SAVE_AUDIO="true"
export VOICEMODE_AUDIO_FORMAT="pcm"
export VOICEMODE_TTS_AUDIO_FORMAT="pcm"
export VOICEMODE_STT_AUDIO_FORMAT="mp3"
export VOICEMODE_OPUS_BITRATE="32000"
export VOICEMODE_MP3_BITRATE="64k"
オーディオフォーマット設定
Voice Modeは、最適なリアルタイムパフォーマンスを得るために、TTSストリーミングにデフォルトで PCM オーディオフォーマットを使用します。
- PCM (TTSのデフォルト): ゼロ遅延、最適なストリーミングパフォーマンス、非圧縮
- MP3: 幅広い互換性、アップロード用の良好な圧縮率
- WAV: 非圧縮、ローカル処理に適しています
- FLAC: 損失のない圧縮、アーカイブに適しています
- AAC: 良好な圧縮率、Appleエコシステム
- Opus: 小さなファイルサイズですが、ストリーミングには推奨されません (品質問題があります)
オーディオフォーマットは、プロバイダーの機能に対して自動的に検証され、必要に応じてサポートされるフォーマットにフォールバックします。
ローカルSTT/TTSサービス
プライバシーを重視するまたはオフラインでの使用のために、Voice Modeはローカルの音声サービスをサポートしています。
- Whisper.cpp - OpenAI互換APIを持つローカルの音声認識
- Kokoro - 複数の音声オプションを持つローカルの音声合成
これらのサービスは、OpenAIと同じAPIインターフェースを提供するため、クラウドとローカルの処理をシームレスに切り替えることができます。
OpenAI API互換の利点
OpenAIのAPI標準を厳密に遵守することで、Voice Modeは強力な展開の柔軟性を提供します。
- 🔀 透過的なルーティング: ユーザーは、Voice Modeの外部で独自のAPIプロキシまたはゲートウェイを実装し、カスタムロジック (コスト、遅延、可用性など) に基づいてリクエストを異なるプロバイダーにルーティングできます。
- 🎯 モデル選択: Voice Modeの設定を変更することなく、リクエストごとに最適なモデルを選択するルーティングレイヤーを展開できます。
- 💰 コスト最適化: 高価なクラウドAPIと無料のローカルモデルをバランスさせるインテリジェントなルーターを構築できます。
- 🔧 ロックインのない柔軟性:
BASE_URL を変更するだけでプロバイダーを切り替えることができ、コードの変更は必要ありません。
例: OPENAI_BASE_URL をカスタムルーターに設定するだけです。
export OPENAI_BASE_URL="https://router.example.com/v1"
export OPENAI_API_KEY="your-key"
OpenAI SDKは自動的にこれを処理するため、Voice Modeの設定は必要ありません!
アーキテクチャ
┌─────────────────────┐ ┌──────────────────┐ ┌─────────────────────┐
│ Claude/LLM │ │ LiveKit Server │ │ Voice Frontend │
│ (MCP Client) │◄────►│ (Optional) │◄───►│ (Optional) │
└─────────────────────┘ └──────────────────┘ └─────────────────────┘
│ │
│ │
▼ ▼
┌─────────────────────┐ ┌──────────────────┐
│ Voice MCP Server │ │ Audio Services │
│ • converse │ │ • OpenAI APIs │
│ • listen_for_speech│◄───►│ • Local Whisper │
│ • check_room_status│ │ • Local TTS │
│ • check_audio_devices └──────────────────┘
└─────────────────────┘
トラブルシューティング
一般的な問題
- マイクアクセスができない: ターミナル/アプリケーションのシステムパーミッションを確認してください。
- WSL2ユーザー: WSL2マイクアクセスガイド を参照してください。
- UVが見つからない:
curl -LsSf https://astral.sh/uv/install.sh | sh でインストールしてください。
- OpenAI APIエラー:
OPENAI_API_KEY が正しく設定されていることを確認してください。
- オーディオ出力がない: システムのオーディオ設定と使用可能なデバイスを確認してください。
デバッグモード
詳細なログとオーディオファイルの保存を有効にします。
export VOICEMODE_DEBUG=true
デバッグ用のオーディオファイルは、~/voicemode_recordings/ に保存されます。
オーディオ診断
診断スクリプトを実行して、オーディオセットアップを確認します。
python scripts/diagnose-wsl-audio.py
これにより、必要なパッケージ、オーディオサービスがチェックされ、具体的な推奨事項が提供されます。
オーディオ保存
すべてのオーディオファイル (TTS出力とSTT入力) を保存するには、以下を実行します。
export VOICEMODE_SAVE_AUDIO=true
オーディオファイルは、~/voicemode_audio/ にタイムスタンプ付きで保存されます。
🎬 デモ
Claude CodeでのVoice Modeの動作を見てみましょう。

Voice Mode with Gemini CLI
GoogleのGemini CLI (Claude Codeの実装) でのVoice Modeの動作を確認してください。
リンク
コミュニティ
関連情報
- 🚀 統合ガイド - すべてのサポートされているツールのセットアップ手順
- 🔧 設定リファレンス - 環境変数とオプション
- 🎤 ローカルサービスのセットアップ - プライバシーのためにTTS/STTをローカルで実行する
- 🐛 トラブルシューティング - 一般的な問題と解決策
📄 ライセンス
MIT - Failmode プロジェクト
プロジェクト統計
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)








