🚀 Context Lens
Context Lens 赋予你的 AI 理解语义的能力,而非仅仅进行关键词匹配,能将任何内容转化为可供 AI 助手搜索的知识库。
🚀 快速开始
添加你的项目
你: 将 ./src 目录下的所有 Python 文件添加到知识库
大语言模型: ✓ 已添加 23 个 Python 文件,共 156 个知识块
你: 认证系统是如何工作的?
大语言模型: 认证系统使用 JWT 令牌。登录流程从 auth/login.py 文件开始,在该文件中验证凭证,然后使用用户 ID 和过期时间生成令牌...
你: 展示所有数据库模型
大语言模型: 根据代码库,主要的数据库模型如下:
1. 用户模型 (models/user.py) - 处理用户账户和认证
2. 文章模型 (models/post.py) - 管理博客文章及其关联关系...
从开源项目中学习
你: 将 https://github.com/fastapi/fastapi 添加到知识库
大语言模型: ✓ 已添加该仓库的 247 个文件,共 1,543 个知识块
你: FastAPI 如何处理依赖注入?
大语言模型: FastAPI 使用复杂的依赖注入系统。fastapi/dependencies.py 中的 Depends() 函数会分析函数签名并自动解析依赖。其工作原理如下...
你: 比较 FastAPI 和 Flask 的路由机制
大语言模型: FastAPI 和 Flask 类似,都使用基于装饰器的路由,但有几个关键区别:1) 使用类型提示进行自动验证;2) 内置异步支持;3) 自动生成 OpenAPI 文档...
分析文档
你: 添加 ./legal/contracts 目录下的所有合同文件
大语言模型: ✓ 已添加 12 个合同文件,共 487 个知识块
你: 查找所有终止条款
大语言模型: 我在 8 个合同中找到了终止条款。以下是总结:
- 服务协议:任何一方需提前 30 天通知
- 供应商合同:若违反保密条款可立即终止...
你: 所有合同的付款条款是什么?
大语言模型: 付款条款因合同类型而异:
- 服务合同:发票日期后 30 天内付款
- 供应商协议:预付 50%,交付时支付 50%...
从 URL 获取文件
你: 添加 https://raw.githubusercontent.com/fastapi/fastapi/master/README.md
大语言模型: ✓ 文档 'README.md' 已成功添加,共 42 个知识块
你: 什么是 FastAPI,它的主要特性有哪些?
大语言模型: FastAPI 是一个现代、快速的 Python 3.7+ Web 框架,用于构建 API。主要特性包括:
- 高性能(与 NodeJS 和 Go 相当)
- 自动生成 API 文档
- 使用类型提示进行验证
- 内置异步支持...
📖 更多示例和查询模式:USAGE_GUIDE.md
✨ 主要特性
- 🔍 语义搜索 - 理解语义,而非仅匹配关键词
- 🚀 零设置 - 无需安装、配置和 API 密钥
- 💾 无服务器存储 - 内置 LanceDB,无需外部数据库
- 🔒 100% 本地和私密 - 所有数据都保存在本地机器上
- 📁 支持本地和 GitHub - 可索引本地文件或公共 GitHub 仓库
- 🎯 智能解析 - 基于语言特性进行分块,以获得更好的搜索结果
📦 安装指南
Kiro IDE
在 .kiro/settings/mcp.json 文件中添加以下内容:
{
"mcpServers": {
"context-lens": {
"command": "uvx",
"args": ["context-lens"],
"autoApprove": ["list_documents", "search_documents"]
}
}
}
重新加载:通过命令面板选择 “MCP: Reload Servers”。
Cursor
在 .cursor/mcp.json 文件中添加以下内容:
{
"mcpServers": {
"context-lens": {
"command": "uvx",
"args": ["context-lens"]
}
}
}
其他 MCP 客户端
对于 Claude Desktop、Continue.dev 或任何兼容 MCP 的客户端,在配置文件中添加以下内容:
{
"mcpServers": {
"context-lens": {
"command": "uvx",
"args": ["context-lens"]
}
}
}
📖 需要详细的设置说明? 请参阅 SETUP.md,其中包含所有客户端的详细设置、编程式用法和配置选项。
💻 使用示例
基础用法
import os
from dotenv import load_dotenv
from mcp import StdioServerParameters, stdio_client
from strands import Agent
from strands.models.openai import OpenAIModel
from strands.tools.mcp import MCPClient
def main():
load_dotenv()
mcp_client = MCPClient(
lambda: stdio_client(
StdioServerParameters(command="uvx", args=["context-lens"])
)
)
model = OpenAIModel(model_id="gpt-4o-mini")
agent = Agent(model=model, tools=[mcp_client])
print("聊天机器人已启动!输入 'quit' 退出。")
while True:
user_input = input("\n你: ").strip()
if user_input.lower() in ['quit', 'exit', 'bye']:
print("再见!")
break
if not user_input:
continue
try:
response = agent(user_input)
print(f"机器人: {response}")
except Exception as e:
print(f"错误: {e}")
if __name__ == "__main__":
main()
示例对话:
你: 将 https://github.com/fastapi/fastapi 添加到知识库
机器人: ✓ 已添加该仓库的 247 个文件,共 1,543 个知识块
你: FastAPI 如何处理依赖注入?
机器人: FastAPI 使用复杂的依赖注入系统...
📖 完整示例:请参阅 SETUP.md,其中包含完整代码和更多框架的使用示例。
📚 详细文档
什么是 Context Lens?
Context Lens 可将任何内容转化为供 AI 助手搜索的 知识库。这个自包含的模型上下文协议(MCP)服务器内置无服务器向量存储(LanceDB),能为对话带来语义搜索功能。你可以将其指向任何内容,如代码库、文档、合同或文本文件,这样你的 AI 就能立即理解并回答关于这些内容的问题。
传统关键词搜索 只能找到包含特定单词的文件。如果未使用确切的术语,就会错过相关内容。
Context Lens 能够理解语义。当你询问 “身份验证” 时,它可以找到关于登录、凭证、令牌、OAuth 和访问控制的代码,即使这些文件中从未使用过 “身份验证” 这个词。
实际演示
想了解 Context-Lens 是如何工作的吗?有趣的是,你可以使用 Context-Lens 来学习 Context-Lens 本身。
演示:使用 Claude Desktop 和 Context-Lens 对本仓库进行索引和查询。无需克隆仓库,也无需滚动查看代码,只需提问和获取答案。
为什么选择 LanceDB?
Context Lens 使用 LanceDB 这一现代无服务器向量数据库:
- 🆓 完全免费且本地运行 - 无需云服务、API 密钥或订阅
- ⚡ 零基础设施 - 嵌入式数据库,仅为磁盘上的一个文件
- 🚀 快速高效 - 基于 Apache Arrow 构建,针对向量搜索进行了优化
- 💾 存储简单 - 单文件数据库,易于备份和移动
可以将其视为 “用于 AI 嵌入的 SQLite”,具备向量搜索的强大功能,且不复杂。
MCP 注册表
Context Lens 已发布到官方 模型上下文协议注册表,名称为 io.github.cornelcroi/context-lens。
📖 注册表详细信息和验证:请参阅 REGISTRY.md 以获取安装验证和注册表信息。
智能解析与分块
Context Lens 并非简单地盲目分割文本,它能理解代码结构,并创建符合语言边界的智能知识块。
区别:普通的分块方式按字符数任意分割代码,常常会在函数中间断开。而智能解析能理解代码结构,创建完整、有意义的知识块。
支持的文件类型
- 🐍 Python (
.py, .pyw) - 函数、类、导入语句
- ⚡ JavaScript/TypeScript (
.js, .jsx, .ts, .tsx, .mjs, .cjs) - 函数、类、导入语句
- 📦 JSON (
.json, .jsonc) - 顶级键、嵌套对象
- 📋 YAML (
.yaml, .yml) - 顶级键、列表、映射
- 📝 Markdown (
.md, .markdown, .mdx) - 标题层次结构、代码块
- 🦀 Rust (
.rs) - 结构体、特征、实现块、函数
- 📄 其他文件 (
.txt, .log, .cpp, .java, 等) - 智能段落/句子分割
优点
✅ 完整的代码单元 - 不会在函数或类中间分割
✅ 保留上下文 - 文档字符串、注释和结构保持完整
✅ 更好的搜索效果 - 可找到完整、易于理解的代码片段
✅ 自动化 - 无需配置,根据文件扩展名自动工作
📖 想了解其工作原理? 请查看 PARSING_EXAMPLES.md 以获取详细示例。
可添加的内容
Context Lens 可处理来自多个来源的文本文件:
- 📁 本地文件和文件夹 - 你的项目、文档、任何文本文件
- 🌐 GitHub 仓库 - 公共仓库、特定分支、目录或文件
- 🔗 直接文件 URL - 任何可通过 HTTP/HTTPS 访问的文件
- 📄 文档 - 合同、政策、研究论文、技术文档
支持的文件类型:.py, .js, .ts, .java, .cpp, .go, .rs, .rb, .php, .json, .yaml, .md, .txt, .sh 等(25 种以上文件扩展名)
最大文件大小:10 MB(可通过 MAX_FILE_SIZE_MB 环境变量进行配置)
示例:
./src/ - 本地目录/path/to/file.py - 单个本地文件https://github.com/fastapi/fastapi - 整个仓库https://github.com/django/django/tree/main/django/contrib/auth - 特定目录https://example.com/config.yaml - 直接文件 URL/path/to/contracts/ - 法律文档
📖 查看更多示例:USAGE_GUIDE.md
可用工具
- 📥 add_document - 添加文件、文件夹或 GitHub URL
- 🔍 search_documents - 对所有内容进行语义搜索
- 📋 list_documents - 浏览已索引的文档
- ℹ️ get_document_info - 获取文档的元数据
- 🗑️ remove_document - 移除特定文档
- 🧹 clear_knowledge_base - 移除所有文档
📖 查看详细示例:USAGE_GUIDE.md
常见问题解答
与 GitHub 的 MCP 服务器相比如何?
它们用途不同且相互补充:
Context Lens 更适合:
- 🧠 语义理解 - “查找身份验证代码” 可以返回关于登录、凭证、令牌、OAuth 的内容,即使没有确切的关键词
- 📚 学习代码库 - 询问 “X 如何工作?” 可以在整个项目中获得概念相关的结果
- 🔍 模式发现 - 查找相似的代码模式、错误处理方法或架构决策
- 💾 离线开发 - 一旦完成索引,无需互联网连接即可工作
- 🔒 隐私保护 - 所有处理都在本地进行,无需将数据发送到外部服务
GitHub 的 MCP 服务器更适合:
- 🔧 仓库管理 - 创建问题、管理 PR、处理 CI/CD 操作
- 📊 实时状态 - 始终从 GitHub 获取最新版本
- 🌐 GitHub 特定功能 - 与 GitHub 生态系统集成(Actions、Projects 等)
关键区别:Context Lens 只需克隆一次并对所有内容进行索引,以实现快速语义搜索(离线)。GitHub MCP 每次查询都会进行 API 调用,以实现实时访问(在线)。使用 Context Lens 来理解代码,使用 GitHub MCP 来管理仓库。
为什么首次运行很慢?
首次使用时会下载嵌入模型(约 100MB),此操作仅需执行一次。
是否需要 API 密钥?
不需要!Context Lens 完全在本地运行,无需 API 密钥和云服务。
数据存储在哪里?
Context-Lens 将数据存储在特定平台的目录中:
- macOS:
~/Library/Application Support/context-lens/
- Linux:
~/.local/share/context-lens/
- Windows:
%LOCALAPPDATA%\context-lens\
你可以通过设置 CONTEXT_LENS_HOME 环境变量来更改基础目录:
{
"mcpServers": {
"context-lens": {
"command": "uvx",
"args": ["context-lens"],
"env": {
"CONTEXT_LENS_HOME": "/path/to/your/data"
}
}
}
}
或者使用 LANCE_DB_PATH(数据库)和 EMBEDDING_CACHE_DIR(模型)覆盖单个路径。
可以用于私有代码吗?
可以!所有处理都在本地进行,不会将任何数据发送到外部服务。
占用多少磁盘空间?
模型约占用 100MB,每个文本块约占用 1KB。一个 10MB 的代码库大约会使用 5 - 10MB 的数据库空间。
📖 更多问题:TROUBLESHOOTING.md
文档资源
- 📖 设置指南 - 所有客户端的详细设置和配置选项
- 📚 使用指南 - 示例、查询和最佳实践
- 🎨 解析示例 - 智能解析的工作原理
- 🔧 故障排除 - 常见问题和解决方案
- ⚙️ 技术细节 - 架构、技术栈和性能
- 📋 注册表信息 - MCP 注册表验证和安装
- 🤝 贡献指南 - 如何贡献、路线图
- 📦 发布指南 - MCP 注册表发布流程(适用于维护者)
贡献说明
欢迎贡献代码!请按以下步骤操作:
- 首先创建一个 issue 讨论你的想法
- 在开始工作前获得批准
- 提交 PR 并引用相关 issue
详细信息请参阅 CONTRIBUTING.md。
🔧 技术细节
架构
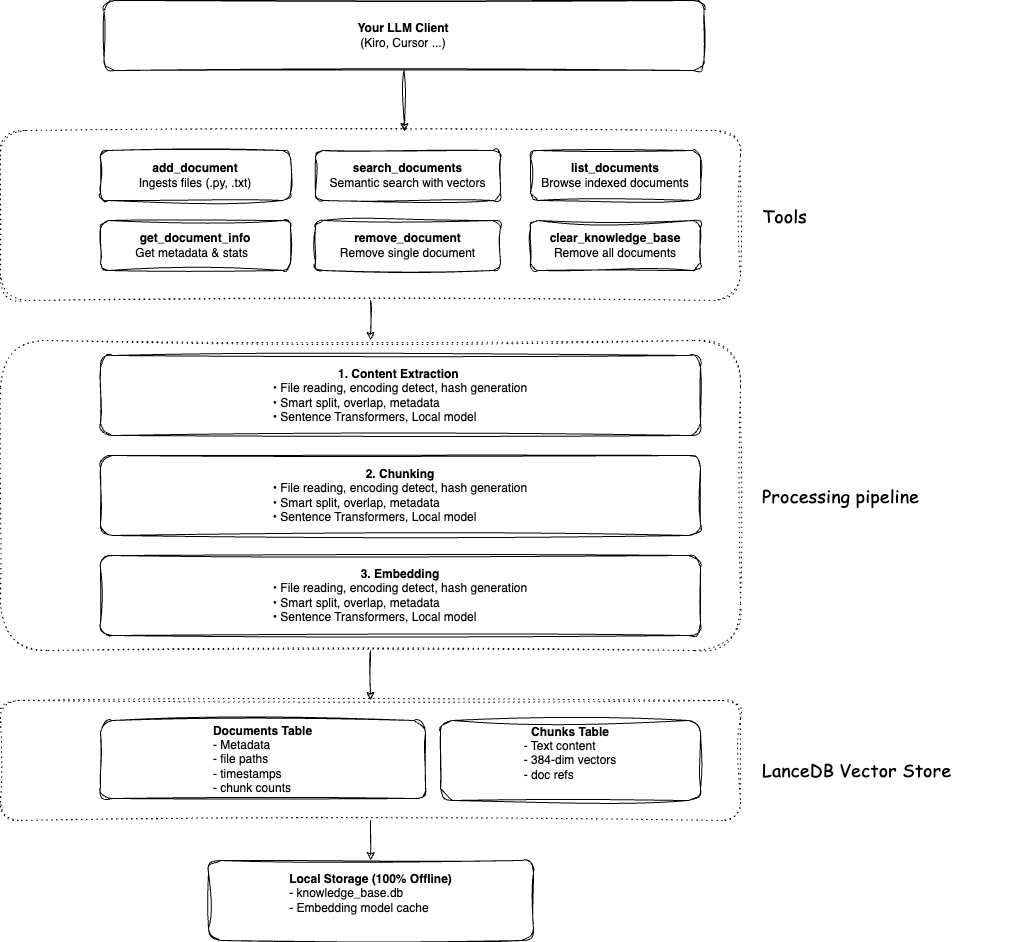
工作原理
当你向 Context Lens 添加内容时,它并非简单地将文本存储到数据库中,实际过程如下:
智能读取:Context Lens 会检测文件类型并使用专门的解析器。对于 Python 文件,使用 AST 解析;对于 JSON 文件,进行结构化解析;对于 Markdown 文件,按标题进行分割。这样可以保留内容的自然结构。
有意义的分块:内容会被智能分块,而非按任意字符限制分割,例如完整的函数、逻辑段落或完整的部分。代码不会在函数中间被分割。
语义向量:每个知识块会使用本地嵌入模型转换为 384 维向量。这些向量捕获语义,而非仅关注单词。“身份验证” 和 “登录系统” 会转换为相似的向量,即使它们没有共同的单词。
本地存储:所有内容都存储在 LanceDB 中,这是一个无服务器向量数据库,仅为磁盘上的一个文件。无需云服务和 API 调用,完全私密。
概念搜索:当你提出问题时,问题也会转换为向量。Context Lens 会查找具有相似向量(相似语义)的知识块,并按相关性排序。你将获得基于概念的答案,而非基于关键词匹配。
技术规格
| 组件 |
详情 |
| 嵌入模型 |
sentence-transformers/all-MiniLM-L6-v2 |
| 向量维度 |
384 维 |
| 模型大小 |
约 90MB(首次使用时下载) |
| 分块大小 |
1000 字符(默认,可配置) |
| 分块重叠 |
200 字符(默认,可配置) |
| 向量数据库 |
LanceDB(无服务器,基于文件) |
| 存储格式 |
Apache Arrow 列式格式 |
| 搜索方法 |
余弦相似度 |
| 处理方式 |
100% 本地处理,无需外部 API 调用 |
📖 想要自定义? 请参阅 SETUP.md 以获取配置选项,参阅 TECHNICAL.md 以获取性能基准测试。
📄 许可证
本项目采用 MIT 许可证,详情请参阅 LICENSE。
如果你觉得这个项目有用,请给它加星! ⭐
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)













