🚀 Context Lens
AIにキーワードの一致だけでなく、意味を理解する能力を与えます。



🚀 クイックスタート
プロジェクトの追加
You: Add all Python files from ./src to the knowledge base
LLM: ✓ Added 23 Python files with 156 chunks
You: How does the authentication system work?
LLM: The authentication system uses JWT tokens. The login flow starts in
auth/login.py where credentials are validated, then a token is generated
with the user's ID and expiration time...
You: Show me all the database models
LLM: Based on the codebase, here are the main database models:
1. User model (models/user.py) - handles user accounts and authentication
2. Post model (models/post.py) - manages blog posts with relationships...
オープンソースから学ぶ
You: Add https://github.com/fastapi/fastapi to the knowledge base
LLM: ✓ Added 247 files from repository with 1,543 chunks
You: How does FastAPI handle dependency injection?
LLM: FastAPI uses a sophisticated dependency injection system. The Depends()
function in fastapi/dependencies.py analyzes function signatures and
automatically resolves dependencies. Here's how it works...
You: Compare FastAPI's routing to Flask
LLM: FastAPI uses decorator-based routing similar to Flask, but with key
differences: 1) Type hints for automatic validation, 2) Async support
built-in, 3) Automatic OpenAPI documentation generation...
ドキュメントの分析
You: Add all contracts from ./legal/contracts
LLM: ✓ Added 12 contract documents with 487 chunks
You: Find all termination clauses
LLM: I found termination clauses in 8 contracts. Here's a summary:
- Service Agreement: 30-day notice required for either party
- Vendor Contract: Immediate termination for breach of confidentiality...
You: What are the payment terms across all contracts?
LLM: Payment terms vary by contract type:
- Service contracts: Net 30 days from invoice date
- Vendor agreements: 50% upfront, 50% on delivery...
URLからファイルを取得
You: Add https://raw.githubusercontent.com/fastapi/fastapi/master/README.md
LLM: ✓ Document 'README.md' added successfully with 42 chunks
You: What is FastAPI and what are its key features?
LLM: FastAPI is a modern, fast web framework for building APIs with Python 3.7+.
Key features include:
- Fast performance (on par with NodeJS and Go)
- Automatic API documentation
- Type hints for validation
- Async support built-in...
📖 詳細な例とクエリパターン: USAGE_GUIDE.md
✨ 主な機能
- 🔍 意味検索 - キーワードだけでなく、意味を理解します
- 🚀 ゼロセットアップ - インストール不要、設定不要、APIキー不要
- 💾 サーバーレスストレージ - 組み込みのLanceDBを使用し、外部データベース不要
- 🔒 100% ローカル&プライベート - すべてのデータはあなたのマシン上に留まります
- 📁 ローカルとGitHub - ローカルファイルまたは公開GitHubリポジトリをインデックス化できます
- 🎯 スマートパーシング - 言語を考慮したチャンク分割により、より良い結果を得ます
📦 インストール
Kiro IDE
.kiro/settings/mcp.jsonに追加します:
{
"mcpServers": {
"context-lens": {
"command": "uvx",
"args": ["context-lens"],
"autoApprove": ["list_documents", "search_documents"]
}
}
}
再読み込み: コマンドパレット → "MCP: Reload Servers"
Cursor
.cursor/mcp.jsonに追加します:
{
"mcpServers": {
"context-lens": {
"command": "uvx",
"args": ["context-lens"]
}
}
}
その他のMCPクライアント
Claude Desktop、Continue.dev、またはMCP互換のクライアントの場合:
{
"mcpServers": {
"context-lens": {
"command": "uvx",
"args": ["context-lens"]
}
}
}
📖 詳細なセットアップ手順が必要ですか? すべてのクライアント、プログラムによる使用方法、および設定オプションについては、SETUP.mdを参照してください。
💻 使用例
基本的な使用法
import os
from dotenv import load_dotenv
from mcp import StdioServerParameters, stdio_client
from strands import Agent
from strands.models.openai import OpenAIModel
from strands.tools.mcp import MCPClient
def main():
load_dotenv()
mcp_client = MCPClient(
lambda: stdio_client(
StdioServerParameters(command="uvx", args=["context-lens"])
)
)
model = OpenAIModel(model_id="gpt-4o-mini")
agent = Agent(model=model, tools=[mcp_client])
print("Chatbot started! Type 'quit' to exit.")
while True:
user_input = input("\nYou: ").strip()
if user_input.lower() in ['quit', 'exit', 'bye']:
print("Goodbye!")
break
if not user_input:
continue
try:
response = agent(user_input)
print(f"Bot: {response}")
except Exception as e:
print(f"Error: {e}")
if __name__ == "__main__":
main()
会話の例:
You: Add https://github.com/fastapi/fastapi to the knowledge base
Bot: ✓ Added 247 files from repository with 1,543 chunks
You: How does FastAPI handle dependency injection?
Bot: FastAPI uses a sophisticated dependency injection system...
📖 完全な例: 完全なコードとその他のフレームワークについては、SETUP.mdを参照してください。
📚 ドキュメント
Context Lensとは?
Context Lensは、あらゆるコンテンツをAIアシスタント用の検索可能な知識ベースに変換します。組み込みのサーバーレスベクトルストレージ(LanceDB)を備えたこの自己完結型のモデルコンテキストプロトコル(MCP)サーバーは、会話に意味検索をもたらします。コードベース、ドキュメント、契約書、またはテキストファイルなど、あらゆるコンテンツを指定すると、AIはすぐにコンテンツを理解し、質問に答えることができます。
従来のキーワード検索は、特定の単語を含むファイルを見つけます。正確な用語を見逃すと、コンテンツも見逃します。
Context Lensは意味を理解します。「認証」について尋ねると、「認証」という単語を使用していないファイルでも、ログイン、資格情報、トークン、OAuth、およびアクセス制御に関するコードを見つけることができます。
実際に動作を確認する
Context-Lensの動作を理解したいですか?面白いことに、Context-Lensを使ってContext-Lensについて学ぶことができます。
デモ: Context-Lensを使用したClaude Desktopで、このリポジトリ自体をインデックス化してクエリを実行します。git cloneもコードをスクロールする必要もなく、質問と回答だけです。
なぜLanceDBを使用するのか?
Context LensはLanceDB - 最新のサーバーレスベクトルデータベースを使用します:
- 🆓 完全に無料&ローカル - クラウドサービス、APIキー、またはサブスクリプション不要
- ⚡ インフラストラクチャ不要 - 組み込みデータベースで、ディスク上の単一のファイルです
- 🚀 高速&効率的 - Apache Arrowをベースに構築され、ベクトル検索に最適化されています
- 💾 シンプルなストレージ - 単一ファイルのデータベースで、バックアップや移動が簡単です
「AI埋め込み用のSQLite」と考えてください - 複雑さを伴わずにベクトル検索のすべての機能を備えています。
スマートパーシングとチャンク分割
Context Lensは、テキストを無差別に分割するのではなく、コード構造を理解し、言語の境界を尊重するインテリジェントなチャンクを作成します。
違い: 一般的なチャンク分割は、文字数でコードを任意に分割するため、関数を途中で分割することがよくあります。スマートパーシングは、コードの構造を理解し、完全で意味のあるチャンクを作成します。
サポートされるファイルタイプ
- 🐍 Python (
.py, .pyw) - 関数、クラス、インポート
- ⚡ JavaScript/TypeScript (
.js, .jsx, .ts, .tsx, .mjs, .cjs) - 関数、クラス、インポート
- 📦 JSON (
.json, .jsonc) - トップレベルのキー、ネストされたオブジェクト
- 📋 YAML (
.yaml, .yml) - トップレベルのキー、リスト、マッピング
- 📝 Markdown (
.md, .markdown, .mdx) - ヘッダー階層、コードブロック
- 🦀 Rust (
.rs) - 構造体、トレイト、implブロック、関数
- 📄 その他のファイル (
.txt, .log, .cpp, .java, など) - インテリジェントな段落/文の分割
利点
✅ 完全なコード単位 - 関数やクラスを途中で分割することはありません
✅ コンテキストの保持 - ドキュメント文字列、コメント、および構造がそのまま維持されます
✅ より良い検索 - 完全で理解しやすいコードスニペットを見つけることができます
✅ 自動化 - 設定不要、ファイル拡張子に基づいて動作します
📖 動作を確認したいですか? 詳細な例については、PARSING_EXAMPLES.mdを参照してください。
追加できるもの
Context Lensは、複数のソースからのテキストベースのファイルで動作します:
- 📁 ローカルファイルとフォルダ - あなたのプロジェクト、ドキュメント、任意のテキストファイル
- 🌐 GitHubリポジトリ - 公開リポジトリ、特定のブランチ、ディレクトリ、またはファイル
- 🔗 直接のファイルURL - HTTP/HTTPSでアクセス可能な任意のファイル
- 📄 ドキュメント - 契約書、ポリシー、研究論文、技術ドキュメント
サポートされるファイルタイプ: .py, .js, .ts, .java, .cpp, .go, .rs, .rb, .php, .json, .yaml, .md, .txt, .sh, など(25以上の拡張子)
最大ファイルサイズ: 10 MB(MAX_FILE_SIZE_MB環境変数で設定可能)
例:
./src/ - ローカルディレクトリ/path/to/file.py - 単一のローカルファイルhttps://github.com/fastapi/fastapi - 全体のリポジトリhttps://github.com/django/django/tree/main/django/contrib/auth - 特定のディレクトリhttps://example.com/config.yaml - 直接のファイルURL/path/to/contracts/ - 契約書
📖 詳細な例: USAGE_GUIDE.md
利用可能なツール
- 📥 add_document - ファイル、フォルダ、またはGitHubのURLを追加します
- 🔍 search_documents - すべてのコンテンツを対象に意味検索を行います
- 📋 list_documents - インデックス化されたドキュメントを閲覧します
- ℹ️ get_document_info - ドキュメントのメタデータを取得します
- 🗑️ remove_document - 特定のドキュメントを削除します
- 🧹 clear_knowledge_base - すべてのドキュメントを削除します
📖 詳細な例: USAGE_GUIDE.md
よくある質問 (FAQ)
これはGitHubのMCPサーバーとどう違いますか?
それぞれ異なる目的を持ち、互いに補完し合います:
Context Lensの方が優れている点:
- 🧠 意味理解 - 「認証コードを見つける」という質問で、「認証」という単語がなくても、ログイン、資格情報、トークン、OAuthに関するコードが返されます
- 📚 コードベースの学習 - 「Xはどのように動作するか」と質問すると、プロジェクト全体で概念的に関連する結果が得られます
- 🔍 パターン発見 - 似たコードパターン、エラーハンドリングのアプローチ、またはアーキテクチャの決定を見つけることができます
- 💾 オフライン開発 - 一度インデックス化すると、インターネット接続なしでも動作します
- 🔒 プライバシー - すべての処理はローカルで行われ、外部サービスにデータは送信されません
GitHubのMCPサーバーの方が優れている点:
- 🔧 リポジトリ管理 - イシューの作成、PRの管理、CI/CD操作の処理
- 📊 リアルタイム状態 - 常にGitHubから最新バージョンを取得します
- 🌐 GitHub固有の機能 - GitHubのエコシステム(Actions、Projectsなど)と統合されます
主な違い: Context Lensは一度クローンし、すべてをインデックス化して高速な意味検索を行います(オフライン)。GitHub MCPは、クエリごとにAPI呼び出しを行い、リアルタイムアクセスを提供します(オンライン)。Context Lensを使用してコードを理解し、GitHub MCPを使用してリポジトリを管理します。
初回実行が遅いのはなぜですか?
初回使用時に埋め込みモデル(約100MB)がダウンロードされます。これは一度だけ行われます。
APIキーは必要ですか?
いいえ!Context Lensは完全にローカルで動作します。APIキーもクラウドサービスも必要ありません。
データはどこに保存されますか?
Context-Lensは、データをプラットフォーム固有のディレクトリに保存します:
- macOS:
~/Library/Application Support/context-lens/
- Linux:
~/.local/share/context-lens/
- Windows:
%LOCALAPPDATA%\context-lens\
CONTEXT_LENS_HOME環境変数を設定することで、ベースディレクトリを変更することができます:
{
"mcpServers": {
"context-lens": {
"command": "uvx",
"args": ["context-lens"],
"env": {
"CONTEXT_LENS_HOME": "/path/to/your/data"
}
}
}
}
または、LANCE_DB_PATH(データベース)とEMBEDDING_CACHE_DIR(モデル)で個々のパスを上書きすることもできます。
これをプライベートコードで使用できますか?
はい!すべての処理はローカルで行われます。外部サービスに何も送信されません。
どれくらいのディスク容量を使用しますか?
モデルに約100MB + テキストチャンクごとに約1KB。10MBのコードベースでは、約5 - 10MBのデータベース容量が使用されます。
📖 その他の質問: TROUBLESHOOTING.md
その他のドキュメント
- 📖 セットアップガイド - すべてのクライアントの詳細なセットアップ、設定オプション
- 📚 使用ガイド - 例、クエリ、およびベストプラクティス
- 🎨 パーシングの例 - スマートパーシングの動作方法
- 🔧 トラブルシューティング - 一般的な問題と解決策
- ⚙️ 技術的詳細 - アーキテクチャ、スタック、およびパフォーマンス
- 📋 レジストリ情報 - MCPレジストリの検証とインストール
- 🤝 コントリビュートガイド - コントリビュートの方法、ロードマップ
- 📦 公開ガイド - MCPレジストリの公開プロセス(メンテナー向け)
🔧 技術詳細
アーキテクチャ
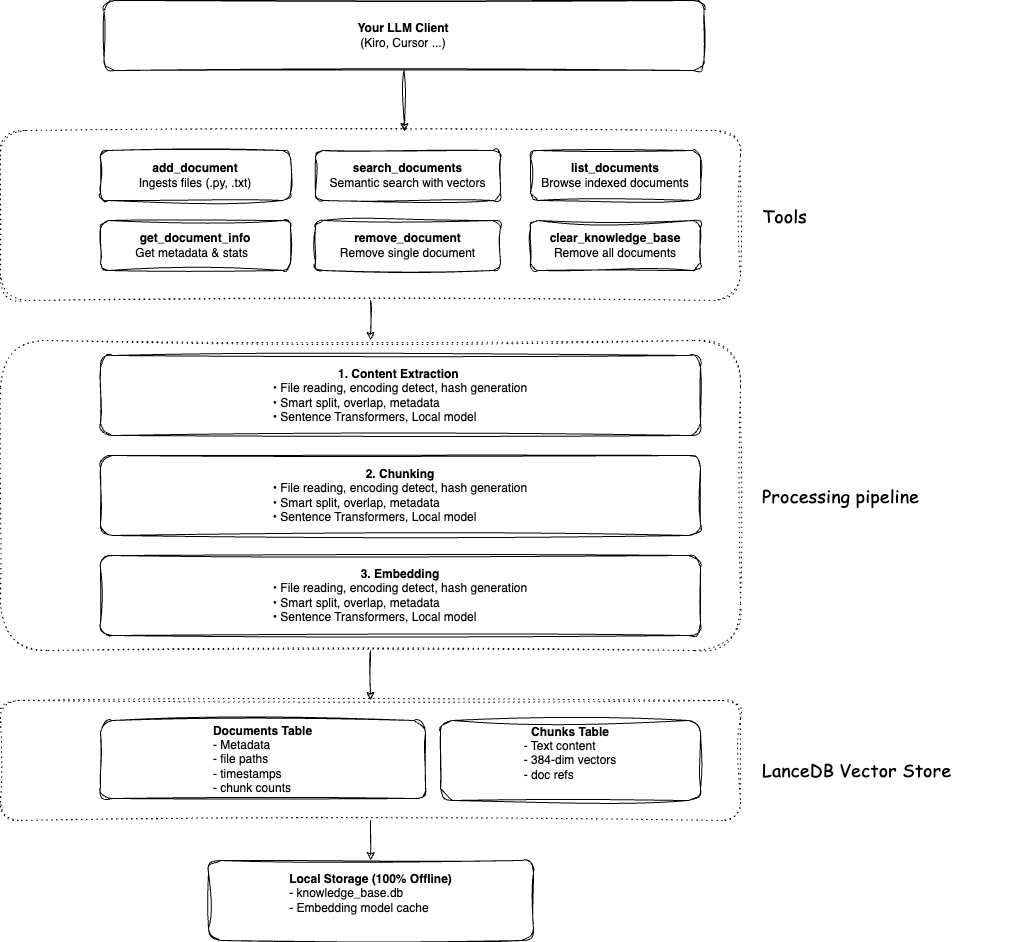
動作原理
コンテンツをContext Lensに追加すると、単にテキストをデータベースに投入するだけではありません。実際には以下のようなことが行われます:
スマートな読み取り: Context Lensはファイルタイプを検出し、専用のパーサーを使用します。PythonファイルはASTパーシングで分析され、JSONは構造的にパースされ、Markdownはヘッダーで分割されます。これにより、コンテンツの自然な構造が保持されます。
意味のあるチャンク: 任意の文字制限ではなく、コンテンツはインテリジェントにチャンク化されます - 完全な関数、論理的な段落、完全なセクション。コードは関数の途中で分割されることはありません。
意味ベクトル: 各チャンクは、ローカルの埋め込みモデルを使用して384次元のベクトルに変換されます。これらのベクトルは、単語だけでなく意味を捉えます。「認証」と「ログインシステム」は、共通の単語がなくても、似たベクトルになります。
ローカルストレージ: すべてがLanceDB - ディスク上の単一のファイルであるサーバーレスベクトルデータベースに保存されます。クラウドサービスやAPI呼び出しは必要ありません。完全にプライベートです。
概念検索: 質問すると、それもベクトルに変換されます。Context Lensは、似たベクトル(似た意味)を持つチャンクを見つけ、関連性でランク付けします。キーワードの一致ではなく、概念に基づいた回答が得られます。
技術仕様
| プロパティ |
詳細 |
| 埋め込みモデル |
sentence-transformers/all-MiniLM-L6-v2 |
| ベクトル次元数 |
384次元 |
| モデルサイズ |
~90MB(初回使用時にダウンロード) |
| チャンクサイズ |
1000文字(デフォルト、設定可能) |
| チャンクオーバーラップ |
200文字(デフォルト、設定可能) |
| ベクトルデータベース |
LanceDB(サーバーレス、ファイルベース) |
| ストレージ形式 |
Apache Arrow列形式 |
| 検索方法 |
コサイン類似度 |
| 処理 |
100%ローカル、外部API呼び出しなし |
📖 カスタマイズしたいですか? 設定オプションについてはSETUP.mdを、パフォーマンスベンチマークについてはTECHNICAL.mdを参照してください。
📄 ライセンス
MITライセンス - 詳細についてはLICENSEを参照してください。
このリポジトリが役に立った場合は、スターをつけてください! ⭐
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)













